《深度探索Linux系统虚拟化》学习笔记
本文最后更新于:2025年6月25日 上午
一、CPU虚拟化
1.1 x86CPU虚拟化
论文“Formal Requirements for Virtualizable Third GenerationArchitectures”中提出了虚拟化的3个条件:
- 等价性,即VMM需要在宿主机上为虚拟机模拟出一个本质上与物理机一致的环境
- 高效性,即虚拟机指令执行的性能与其在物理机上运行相比并无明显损耗
- 资源控制,即VMM可以完全控制系统资源。由VMM控制协调宿主机资源给各个虚拟机,而不能由虚拟机控制了宿主机的资源。
1.1.1陷入和模拟
满足上述虚拟化的一个解决方案是陷入和模拟(Trap and Emulate)模型
处理器分为两种运行模式:系统模式和用户模式
CPU的指令也分为:特权指令和非特权指令
特权指令只能在系统模式运行,如果在用户模式运行就将触发处理器异常。内核运行在系统模式
在陷入和模拟模型下,虚拟机的用户程序仍然运行在用户模式,但是虚拟机的内核也将运行在用户模式,这种方式称为特权级压缩(Ring Compression)。在这种方式下,虚拟机中的非特权指令直接运行在处理器上。这样的好处就是高效,指令无需vmm干预可以直接运行在处理器上
对于虚拟机中的特权指令,因为是在用户模式下运行,将触发处理器异常,从而陷入VMM中,由VMM代理虚拟机完成系统资源的访问,即所谓的模拟(emulate)
1.1.2 x86架构虚拟化的障碍
修改系统资源的,或者在不同模式下行为有不同表现的,都属于敏感指令
在虚拟化场景下,VMM需要监测这些敏感指令。一个支持虚拟化的体系架构的敏感指
令都应该属于特权指令,即在非特权级别执行这些敏感指令时CPU会抛出异常,进入VMM的异常处理函数,从而实现了控制VM访问敏感资源的目的
x86架构并不是所有的敏感指令都是特权指令,有些敏感指令在非特权模式下执行时并不会抛出异常,此时VMM就无法拦截处理VM的行为了
那么问题来了,为什么既要有敏感指令,又要有特权指令,这是出于什么考虑呢?或者说直接简单粗暴的把所有的敏感指令都归为特权指令不就可以了?
- 提高性能和效率: 敏感指令允许一些敏感操作在用户态下执行,从而提高性能和效率。在某些情况下,将敏感操作作为普通指令执行可以减少特权级别的切换和开销,提高应用程序的执行效率。
- 灵活性和可编程性: 敏感指令允许应用程序在用户态下执行一些低级的硬件操作,以实现更灵活的编程和功能。这可以使应用程序更加自由地控制硬件,实现一些特定的功能或优化。
以修改FLAGS寄存器中的IF(Interrupt Flag)为例:
- 首先使用指令pushf将FLAGS寄存器的内容压到栈中
- 然后将栈顶的IF清零
- 最后使用popf指令从栈中恢复FLAGS寄存器
如果虚拟机内核没有运行在ring 0,x86的CPU并不会抛出异常,而只是忽略指令popf
解决方案:试用xen的方式,修改操作系统源码(也即是半虚拟化方式);另一种是软件层面的二进制翻译
静态翻译:
- 运行前扫描整个可执行文件,对敏感指令进行翻译,形成一个新的文件
- 缺点:必须提前处理,而且对于有些指令只有在运行时才会产生的副作用,无法静态处理
动态翻译:
- 在运行时以代码块为单元动态地修改二进制代码
- 在很多VMM中得到应用,而且优化的效果非常不错
1.1.3vmx
Intel开发了VT技术以支持虚拟化,为CPU增加了Virtual-Machine
Extensions,简称VMX
由于之前的软件解决方案引入了巨大开销和复杂性,于是,Intel尝试从硬件层面解决这个问题(nm英特尔终于下场了)
控制寄存器 CR3 在 x86 架构中是页目录表的基地址,用于确定当前正在执行的虚拟机的页表。
当使用影子页表(Shadow Page Table)进行虚拟地址(GVA)到物理地址(HPA)的映射时,**虚拟机监控器(VMM)模块需要捕获虚拟机(Guest)每一次设置控制寄存器 CR3 的操作,并将它重定向到影子页表。CR3 寄存器是x86体系结构中的控制寄存器,用于指向页表的物理地址。
GVA(Guest Virtual Address,客户虚拟地址)和 HPA(Host Physical Address,宿主物理地址)之间的映射是指将虚拟机中的内存地址映射到底层物理主机上的内存地址
通过捕获并重定向CR3寄存器的设置操作,VMM能够截获Guest的页表访问并更改其映射方式。VMM会创建和维护一个与Guest页表类似的影子页表,其中包含与真实物理页表相对应的影子页表项。VMM使用影子页表来追踪和管理GVA到HPA的映射,并在必要时进行转换和修改,以提供虚拟化环境的安全隔离和管理。
EPT(Extended Page Tables): EPT 是一种硬件辅助虚拟化技术,由支持虚拟化的处理器提供。它允许虚拟机直接在物理主机上运行,而不需要额外的转换层。在启用 EPT 支持后,处理器会直接处理 GVA 到 HPA 的映射,绕过了 VMM。这意味着
CR3寄存器仍然指向虚拟机的原始页表,而无需引入影子页表。
而当启用了硬件层面的EPT支持后,cr3寄存器不再需要指向影子页表,其仍然指向Guest的进程的页表。因此,VMM无须再捕捉Guest设置cr3寄存器的操作,也就是说,虽然写cr3寄存器是一个特权操作,但这个操作不需要陷入VMM。
一旦启动了CPU的VMX支持,CPU将提供两种运行模式:VMX Root Mode和VMX non-Root Mode,每一种模式都支持ring 0~ring 3。VMM运行在VMX Root Mode,除了支持VMX外,VMXRoot Mode和普通的模式并无本质区别。VM运行在VMX non-Root Mode,Guest无须再采用特权级压缩方式,Guest kernel可以直接运行在VMX non-Root Mode的ring 0中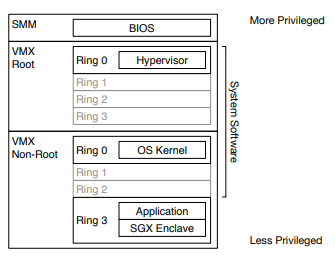
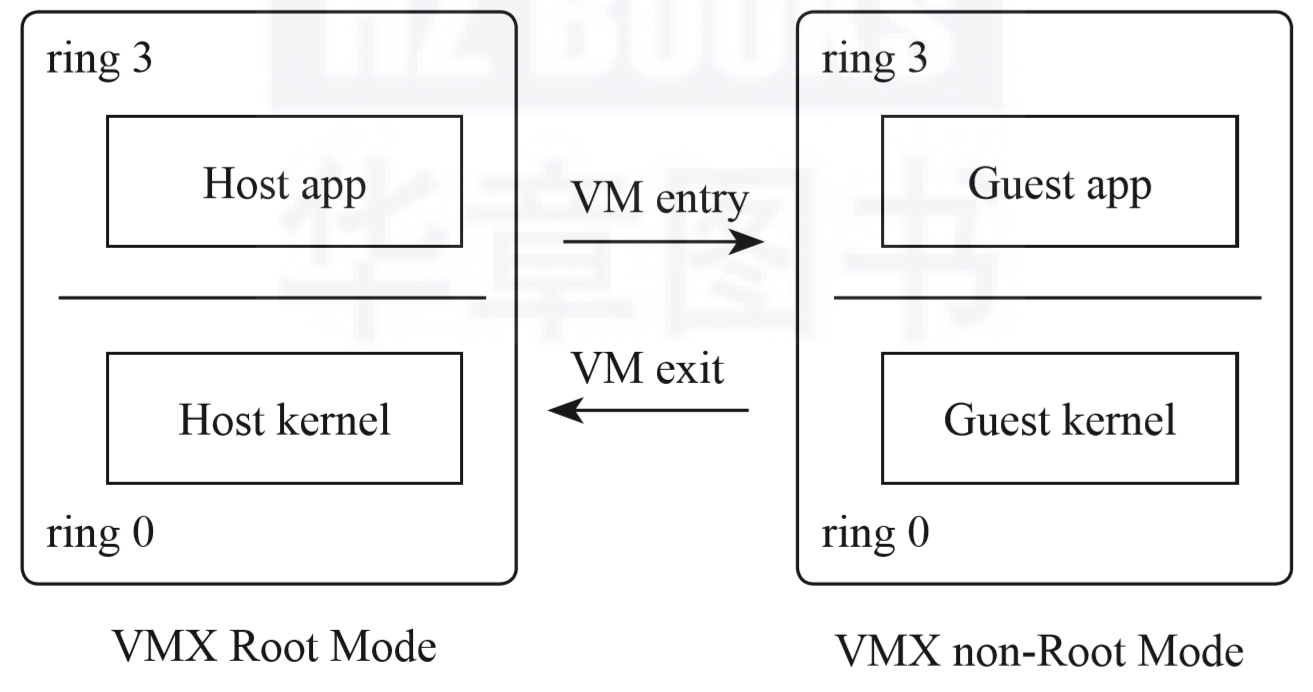
VM entry:
- 处于VMX Root Mode的VMM可以通过执行CPU提供的虚拟化指令VMLaunch切换到VMX non-Root Mode,因为这个过程相当于进入Guest,所以通常也被称为VM entry
VM exit - 当Guest内部执行了敏感指令,比如某些I/O操作后,将触发CPU发生陷入的动作,从VMX non-Root Mode切换回VMX Root Mode,这个过程相当于退出VM,所以也称为VM exit
- 然后VMM将对Guest的操作进行模拟
支持VMX的CPU有以下3点不同:
1)运行于Guest模式时,Guest用户空间的系统调用直接陷入Guest模式的内核空间,而不再是陷入Host模式的内核空间。
系统调用处理:在VMX支持的虚拟化环境中,当Guest运行用户空间程序并进行系统调用时,系统调用不再直接陷入Host模式的内核空间,而是陷入Guest模式的内核空间。这样,Guest内核可以直接处理系统调用,而无需VMM(虚拟机监控器)介入,从而提高了性能
2)对于外部中断,因为需要由VMM控制系统的资源,所以处于Guest模式的CPU收到外部中断后,触发CPU从Guest模式退出到Host模式,由Host内核处理外部中断。处理完中断后,再重新切入Guest模式。为了提高I/O效率,Intel支持外设透传模式,在这种模式下,Guest不必产生VM exit。在“设备虚拟化”一章将讨论这种特殊方式。
3)不再是所有的特权指令都会导致处于Guest模式的CPU发生VM exit。仅当运行敏感指令时才会导致CPU从Guest模式陷入Host模式,因为有的特权指令并不需要由VMM介入处理。
对于一些无需VMM介入的特权指令,CPU可以在Guest模式下直接执行,从而提高虚拟机的性能。
VMX(Virtual Machine Extensions)是Intel处理器的虚拟化扩展技术,它引入了VMCS(Virtual Machine Control Structure)这一数据结构。VMCS用于保存虚拟机的上下文信息,每个Guest虚拟机都有一个对应的VMCS实例。
VMCS记录了虚拟机的状态和配置信息,包括虚拟处理器的寄存器值、控制寄存器设置、虚拟机执行的状态、中断处理、VM exit和VM entry的设置等。VMCS在虚拟化过程中扮演着重要的角色,用于控制虚拟机的运行、实现虚拟机的切换、以及在VM exit和VM entry时保存和恢复虚拟机的状态。
每个Guest虚拟机都有一个对应的VMCS,这些VMCS实例是独立的,彼此之间隔离。当VMM(虚拟机监控器)在宿主机上运行多个虚拟机时,每个虚拟机的VMCS会在VMM的管理下进行创建和维护。VMCS的管理涉及VM entry和VM exit的操作,用于实现Guest和宿主机之间的转换和切换。
注意:每个虚拟机都会有一个唯一的 VMCS,但是每个虚拟机可以有一个或多个 vCPU
在KVM(Kernel-based Virtual Machine)模块中,对于每个虚拟CPU(VCPU),会为其创建一个VMCS(Virtual Machine Control Structure)实例。VMCS用于保存虚拟机的状态信息和控制虚拟机的行为。每个VCPU都有自己独立的VMCS,这样可以实现对不同虚拟机的隔离和管理。
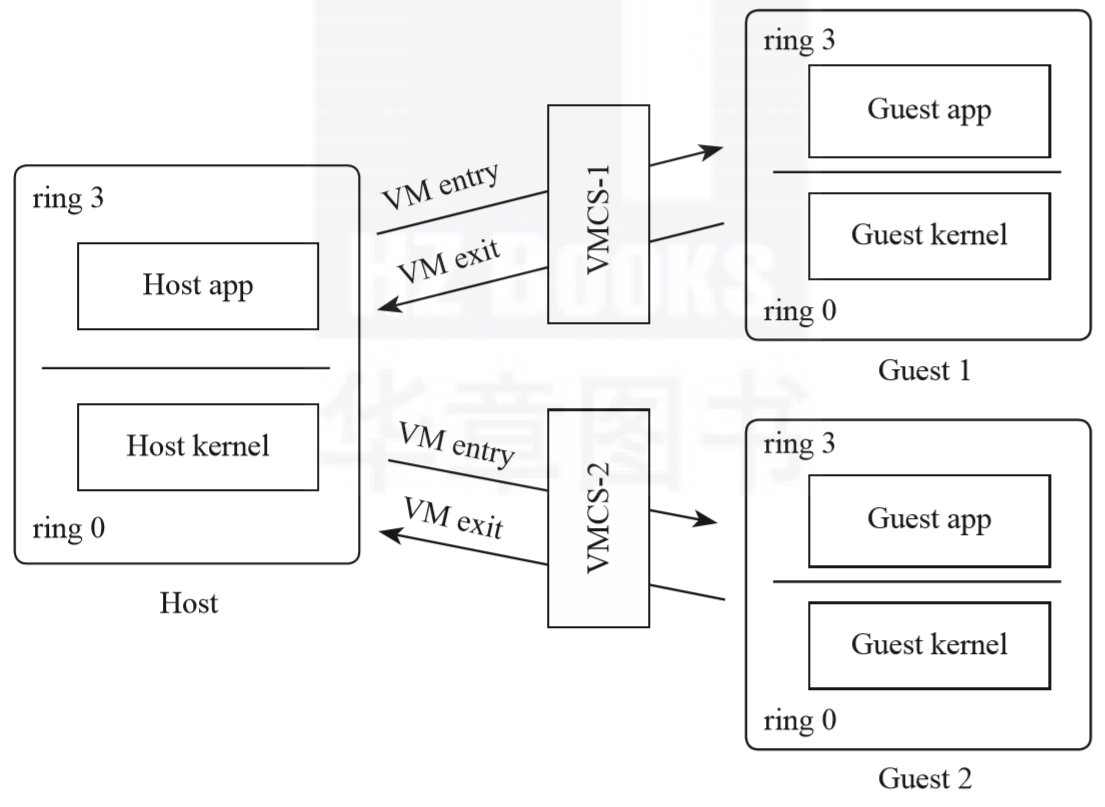
VMCS中主要保存着两大类数据:
- 状态(Host的状态和Guest的状态)
- 行为(控制Guest运行时的行为)
一些数据:
1)Guest-state area(客户机状态区域):该区域保存着虚拟机(Guest)的状态信息。当虚拟机发生VM exit时,Guest的状态会自动保存到这个区域。当虚拟机再次进入(VM entry)时,这些保存的状态会被自动装载到CPU中,使得虚拟机能够从离开状态继续执行,这是硬件层面的自动行为,无需VMM编码干预。
2)Host-state area(宿主机状态区域):该区域保存着宿主机(Host)的状态信息。当虚拟机发生VM entry时,CPU会自动将宿主机状态保存到这个区域。而当虚拟机发生VM exit时,CPU会自动从VMCS中恢复宿主机状态到物理CPU,使得虚拟机退出后宿主机能够继续执行。
3)VM-exit information fields(虚拟机退出信息区域):在虚拟机发生VM exit时,VMM需要知道导致VM exit的原因,以便根据具体情况进行相应的处理。为此,CPU会自动将导致VM exit的原因和一些相关信息保存在这个区域中,供VMM使用。
4)VM-execution control fields(虚拟机执行控制区域):该区域中的各种字段用于控制虚拟机运行时的行为。例如,可以设置是否在Guest访问CR3寄存器时触发VM exit。VM-entry control fields和VM-exit control fields也包含在这个区域中,它们用于控制虚拟机进入(VM entry)和退出(VM exit)时的行为。
在每次准备将物理CPU切换到虚拟机的Guest模式(VM entry)时,KVM会设置物理CPU的VMCS指针,使其指向即将切换到的Guest虚拟机对应的VMCS实例。这样,当物理CPU进入Guest模式后,它会自动使用该VMCS中保存的虚拟机状态信息,并按照VMCS中的配置执行虚拟机的行为。
通过每个VCPU拥有自己的独立VMCS实例,并在切换到Guest模式时设置正确的VMCS指针,KVM能够高效地管理多个虚拟机,并确保虚拟机之间的隔离和资源管理。
在创建VCPU时,KVM模块将为每个VCPU申请一个VMCS,每次CPU准备切入Guest模式时,将设置其VMCS指针指向即将切入的Guest对应的VMCS实例:
1 | |
- 代码中的
vmx_vcpu_load函数用于加载虚拟CPU的VMCS(虚拟机控制结构)。 phys_addr变量存储了vcpu->vmcs的虚拟地址转换后的物理地址。get_cpu()函数用于获取当前CPU的编号。per_cpu(current_vmcs, cpu)是指向当前CPU上活动的VMCS的指针,检查当前活动的VMCS是否与即将加载的vcpu->vmcs相同。- 如果当前活动的VMCS与将要加载的
vcpu->vmcs不同,那么将设置当前活动的VMCS为vcpu->vmcs,表示正在加载该VMCS。 asm volatile (ASM_VMX_VMPTRLD_RAX "; setna %0" ...)是一个内联汇编代码,执行VMCS的加载操作(VMPTRLD),将vcpu->vmcs指向的VMCS加载到CPU中。
per_cpu是Linux内核中用于访问特定CPU本地数据的宏。它是Linux内核中用于多处理器(Multiprocessor,简称MP)和多核(Multicore)系统的一种机制。
在多处理器系统中,每个CPU拥有自己的本地数据,例如线程私有数据或本地缓存。由于多个CPU之间共享内存,直接访问这些本地数据可能会导致数据的不一致性。为了解决这个问题,Linux内核提供了per_cpu宏,它允许开发者声明和使用CPU本地的变量,并根据当前CPU的编号来访问这些变量的正确实例。
per_cpu宏使用特殊的语法,例如per_cpu(var, cpu),其中var是要访问的变量,cpu是指定的CPU编号。该宏会根据当前CPU的编号自动选择正确的实例,从而确保每个CPU都访问自己本地的变量。
1.1.4 VCPU生命周期
对于每个虚拟处理器(VCPU),VMM使用一个线程来代表VCPU这个实体
在Guest运转过程中,每个VCPU基本都在下图所示的状态中不断地转换:(VCPU生命周期)
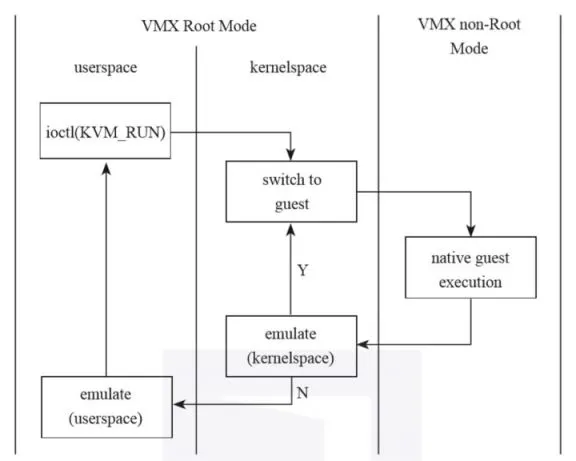
- VCPU准备:在用户空间准备好后,VCPU所在线程向内核中的KVM模块发起ioctl请求KVM_RUN,通知内核可以切入Guest模式运行Guest。
- 切入Guest模式:进入内核态后,KVM模块使用虚拟化指令切入Guest模式。首次运行Guest使用VMLaunch指令,否则使用VMResume指令。
- 在切换过程中,CPU的状态(Host的状态)保存到VMCS中的Host状态区域,非CPU自动保存的状态由KVM负责保存
- 然后,加载存储在VMCS中的Guest的状态到物理CPU,非CPU自动恢复的状态由KVM负责恢复。
- 运行Guest指令:物理CPU运行Guest指令。当执行Guest指令遇到敏感指令时,CPU将从Guest模式切回到Host模式的ring 0,进入Host内核的KVM模块。在切换过程中,CPU的状态(Guest的状态)保存到VMCS中的Guest状态区域,然后加载存储在VMCS中的Host的状态到物理CPU。非CPU自动保存的状态由KVM模块负责保存。
- 处理虚拟机退出:KVM模块从VMCS中读取虚拟机退出原因,尝试在内核中处理。如果内核可以处理,就不必再切换到Host模式的用户态了,直接快速切回Guest。这种退出也称为轻量级虚拟机退出。
- 处理虚拟机退出的复杂情况:如果KVM模块不能处理虚拟机退出,VCPU将再次进行上下文切换,从Host的内核态切换到Host的用户态,由VMM的用户空间部分进行处理。VMM用户空间处理完毕后,再次发起切入Guest模式的指令。
在整个虚拟机运行过程中,步骤1~5循环往复。
下面是KVM切入、切出Guest的代码:
1 | |
在从Guest模式退出时,KVM模块首先调用函数kvm_handle_exit尝试在内核空间处理虚拟机的退出原因。该函数有一个约定:如果在内核空间成功处理虚拟机退出,或者是因为其他干扰(比如外部中断)导致虚拟机退出等无需切换到Host的用户空间,则返回1;否则返回0,表示需要求助KVM的用户空间处理虚拟机退出,例如需要KVM用户空间的模拟设备来处理外设请求。
如果内核空间成功处理了虚拟机的退出(
kvm_handle_exit返回1),在上述代码中即直接跳转到标签again处,然后程序流程会再次切入Guest模式,继续执行Guest的指令。如果函数
kvm_handle_exit返回0,则函数vmx_vcpu_run结束执行,CPU从内核空间返回到用户空间。在用户空间,例如使用kvmtool作为例子,会处理Guest的请求,比如调用模拟设备来处理I/O请求。处理完Guest的请求后,程序重新进入下一轮for循环,kvmtool再次请求KVM模块切入Guest模式,继续执行Guest的指令。
1 | |
1.2虚拟机切入和退出
1.2.1GCC内联汇编
KVM模块中切入Guest模式的代码使用GCC的内联汇编编写
内联汇编基本语法模板如下:
1 | |
- asm为GCC关键字,表示接下来要嵌入汇编代码
- volatile为可选关键字,表示不需要GCC对下面的汇编代码做任何优化
- assembler template是要嵌入的汇编指令,如果内嵌多行汇编指令,则每条指令占用1行,每行指令使用双引号括起来,以后缀
\n\t结尾
1 | |
当使用扩展模式,即包含output、input和clobber list部分时,汇编指令中需要使用两个“%”来引用寄存器,比如%%rax;使用一个“%”来引用输入、输出操作数,比如%1,以便帮助GCC区分寄存器和由C语言提供的操作数
输出操作数(output operands)。输出操作数,用来指示内联汇编指令修改了C代码中的变量。如果有多个输出参数,则需要对每个输出参数进行分隔。
- 输出操作数的格式可以为
[[asmSymbolicName]] constraint (cvariablename),可以为输出操作数指定一个名字asmSymbolicName,汇编指令中可以使用这个名字引用输出操作数。约束部分必须以“=”或者“+”作为前缀,“=”表示只写,“+”表示读写。在前缀之后,就可以是各种约束了,比如“=a”表示先将结果输出至rax/eax寄存器,然后再由rax/eax寄存器更新相应的输出变量。cvariablename为代码中的C变量名字,需要使用括号括起来 - 也可以使用序号引用操作数比如输出操作数有两个,那么可以用**%0引用第1个输出操作数,%1引用第2个操作数**,以此类推。
- 输出操作数的格式可以为
输入操作数(input operands)。与输出操作数相似。输入操作数来自C代码中的变量或者表达式。
- 除了不必以“=”或者“+”前缀开头外,输入操作数的前缀与输出操作数基本相同。
- 输出操作数的格式可以为
[[asmSymbolicName]] constraint (cvariablename) - 除了寄存器约束外,“i”这个约束,表示这个输入操作数是个立即数(immediateinteger)
- 输出操作数的格式也可以从最后一个输出操作数的序号加1开始,比如输出操作数有两个,输入操作数有3个,那么需要使用%2引用第1个输入操作数,%3引用第2个输入操作数,以此类推。
clobber list
- 汇编指令执行后可能会隐性地影响某些寄存器或者内存的值,如果被影响的寄存器或者内存并没有在输入、输出操作数中列出来,那么需要将这些寄存器或者内存列入clobber list。通过这种方式,内联汇编告知GCC,在执行内联汇编指令后恢复寄存器的值
一个具体的例子:一个加法运算,一个加数是val,值为100,另外一个加数是一个立即数400,计算结果保存到变量sum中
1 | |
在汇编代码中使用了rbx寄存器,而rbx 寄存器没有出现在输出、输入操作数中,所以内联汇编需要把rbx寄存 器列入clobber list中,见第10行代码,告诉GCC汇编指令污染了rbx 寄存器
1.2.2虚拟机切入和退出及相关的上下文保存
1 | |
- line 7 . KVM将宿主机的通用寄存器保存到栈中。当发生VM退出时,KVM从栈中将这些保存的宿主机的通用寄存器恢复到CPU的物理寄存器中。这里,宏R在64位下值为r,32位下为e。
- rdx/edx寄存器是GCC保留的regparm特性,不能放在clobber list中,另外一个rbp/ebp寄存器也不生效,所以KVM手动保存了这两个寄存器
- 从Guest退出到Host时,CPU不会自动保存guest的通用寄存器等寄存器,KVM手动将其保存到了结构体vcpu_vmx中的子结构体中。因此,在Guest退出的那一刻,首先必须要获取结构体vcpu_vmx的实例,也就是第3行代码中的变量vmx,将CPU寄存器中的状态保存到这个vmx中,也就是说,在保存完Guest的状态后,才能进行其他操作,避免破坏Guest的状态。于是,每次从Host切入Guest前的最后一刻,KVM将vmx的地址压入栈顶,然后在Guest退出时从栈顶第一时间取出vmx。
- 如何将vmx压入栈顶呢?参见第47行代码,这里使用了GCC内联汇编的input约束,即在执行汇编代码前,告诉编译器将变量vmx加载到rcx/ecx寄存器,那么在执行第8行代码,即将rcx/ecx寄存器的内容压入栈时,实际上是将变量vmx压入栈顶了。
- 在Guest退出时,CPU会自动将VMCS中Host的rsp/esp寄存器恢复到物理CPU的rsp/esp寄存器中,所以此时可以访问VCPU线程在Host态下的栈。
- 在Guest退出后的第1行代码,即第36行代码,调用xchg指令将栈顶的值和序号%0指代的变量进行交换,根据第47行代码可见,%0指代变量vmx,对应的寄存器是rcx/ecx,也就是说,这行代码将切入Guest之前保存到栈顶的变量vmx的地址恢复到了rcx/ecx寄存器中,%0引用的也是这个地址,那么就可以使用%0引用这个地址保存Guest的寄存器了。
这里上下文有点麻烦,详见书上吧
1.3陷入和模拟
- 虚拟机并不会一直保持在Guest模式,而是需要在某些情况下切换到Host模式。在Host角度看,虚拟机就像是Host上的一个进程,与其他虚拟机一同共享系统资源。
- 虚拟机访问系统资源时,可能需要退出到Host模式,让VMM(虚拟机监控器)代为完成资源访问。例如,虚拟机进行I/O访问时,VMM会处理实际的文件读写或网络传输。类似地,访问设备I/O内存映射的地址空间可能会触发页面异常,需要KVM介入模拟设备处理。
- 虚拟机通常不会直接呈现Host的CPU信息,而是模拟特定的CPU型号。这意味着某些指令如cpuid在Guest模式下无法执行,需要KVM介入模拟这些指令。
- 陷入(或中断)可以是虚拟机主动触发的,比如虚拟机主动请求Host来完成某些任务,也可以是被动触发的,比如外部时钟中断或外设中断。被动触发的陷入通常是需要将CPU资源让给Host或进行特定处理的情况。
1.3.2 特殊指令
在虚拟化环境中,存在一些指令在机制上可以直接在虚拟机的Guest模式下本地运行,但是它们在虚拟化上下文中的语义与非虚拟化环境下完全不同。两个主要的例子是cpuid指令和hlt指令:
cpuid
在虚拟化环境中,对于cpuid指令的模拟是必要的,因为直接在Guest模式下运行该指令会导致获取的是宿主机物理CPU的各种特性
为了保证虚拟机获得正确、一致的CPU特性信息,cpuid指令在虚拟化环境中需要被拦截并进行模拟,以确保虚拟机能够在各种环境下稳定运行,并且获得与实际情况相符的CPU特性信息。
- 虚拟化监控器(VMM)需要在虚拟机执行cpuid指令时介入,模拟CPU的特性信息。由于VMM在虚拟化层面进行模拟,因此模拟的CPU可能支持更多的特性,与物理CPU不完全一致。VMM需要在执行cpuid指令时返回虚拟CPU的特性,以保证虚拟机获得正确的特性信息。
- 虚拟机可能会在不同的宿主机之间迁移,为了确保虚拟机能够在不同环境下一致地运行,cpuid指令需要陷入VMM进行特殊处理。这意味着无论虚拟机在哪个物理主机上运行,其获取的CPU特性信息都应该保持一致,以避免应用程序因特性差异而受到影响。
KVM的用户空间通过cpuid指令获取Host的CPU特征,加上用户空间的配置,定义好VCPU支持的CPU特性,传递给KVM内核模块。
KVM模块在内核中定义了接收来自用户空间定义的CPU特性的结构体:
1 | |
用户空间按照如下结构体kvm_cpuid的格式组织好CPU特性后,通过如下KVM模块提供的接口传递给KVM内核模块:
1 | |
下面这段代码用于在虚拟化环境中模拟处理虚拟机执行 cpuid 指令的情况。通过遍历虚拟机提供的 cpuid_entries 数组,KVM 在其中查找与当前功能号匹配的特性信息,将匹配的特性信息的字段值加载到虚拟 CPU 寄存器中。
1 | |
- 当虚拟机执行
cpuid指令并产生 VM exit 时,KVM会调用kvm_emulate_cpuid函数进行模拟。 vcpu->regs[VCPU_REGS_RAX]中存储了cpuid指令中的功能号,即eax寄存器的值。这个值用来确定要查询的 CPU 特性信息。- 在
vcpu->cpuid_entries数组中,存储了一系列的 CPU 特性信息,每个元素都是一个kvm_cpuid_entry实例,其中包含了不同功能号对应的特性信息。 - 通过遍历
vcpu->cpuid_entries数组,KVM 在其中查找具有与当前功能号匹配的特性信息,即e->function == function。 - 如果找到匹配的特性信息(
best非空),则将该特性信息中的eax、ebx、ecx、edx字段的值分别复制到虚拟 CPU 寄存器vcpu->regs的相应位置,以便在进入虚拟机后,虚拟 CPU 可以从这些寄存器读取 CPU 相关信息和特性。 - 最后,
skip_emulated_instruction函数用于通知 KVM 跳过当前模拟的指令,继续执行下一条指令。
下面这段代码示例是在用户空间中处理虚拟机的 CPU 特性信息,以便在不同类型的宿主机之间迁移虚拟机。具体来说,它通过从 KVM 内核模块获取 CPU 特性信息,并清除不支持 AVX2 指令的特性。
1 | |
hlt
hlt指令是一条汇编指令,用于让处理器进入空闲状态。它的作用是暂停当前处理器的执行,等待外部中断或其他事件的发生。当处理器执行到hlt指令时,它会停止执行指令,并将自己置于低功耗状态,直到有新的中断或事件触发处理器唤醒。
hlt 指令用于让处理器进入停机状态。在开启超线程的处理器中,hlt 指令会停止逻辑核的运行。对于虚拟化环境中的虚拟机,如果允许虚拟机的某个核本地执行 hlt 指令,将导致物理CPU停止运行,但实际上我们只需要停止用于模拟CPU的线程。因此,在虚拟化环境中,虚拟机执行 hlt 指令时需要陷入KVM,由KVM挂起对应的VCPU线程,而不是停止物理CPU的运行。下面代码片段展示了如何在KVM中处理虚拟机执行 hlt 指令,通过设置线程状态和调用内核调度函数,实现了在虚拟机中正确处理 hlt 指令的逻辑。
1 | |
1.3.3 访问具有副作用的寄存器
在虚拟化环境中,Guest访问CPU的某些寄存器时,除了读写寄存器的内容外,还可能产生一些副作用。对于这些具有副作用的访问,CPU需要从Guest模式陷入VMM,由VMM进行模拟,以完成副作用操作。以下是一些典型示例:
- 核间中断(Inter-processor Interrupts): 当Guest访问LAPIC的中断控制寄存器时,例如写入中断控制寄存器,可能触发LAPIC向其他处理器发送核间中断。这种操作的副作用需要由VMM模拟,从而保证在虚拟化环境中的正确处理。
LAPIC,全称为“Local Advanced Programmable Interrupt Controller”,是一种高级可编程中断控制器,常用于多处理器系统中的各个处理器核心之间进行中断的管理和协调。LAPIC负责处理本地(即同一物理处理器上的)中断,以及处理器之间的通信。
2.地址翻译和页表切换: 当Guest切换进程,其内核会设置CR3寄存器指向即将运行的进程的页表。在使用影子页表(Shadow Page Table)机制实现虚拟机地址(GVA)到宿主机物理地址(HPA)的映射时,虚拟机期望物理CPU的CR3寄存器指向KVM为Guest中即将投入运行的进程准备的影子页表。 因此,每当Guest切换进程时,CPU会陷入KVM,KVM将CR3寄存器设置为指向影子页表,以确保正确的地址映射。
在影子页表机制中,KVM需要对处理Guest对控制寄存器CR3的访问进行特殊处理,以便让KVM能够正确地进行虚拟地址到宿主机物理地址的转换。为了实现这个目标,KVM需要在VMCS(Virtual Machine Control Structure,虚拟机控制结构)中的Processor-Based VM-Execution Controls字段中设置特定的标志位,即第15位CR3-load exiting。这个标志位的设置会导致每当Guest访问物理CPU的CR3寄存器时,物理CPU会触发VM exit,即从Guest模式切换到Host模式,然后陷入KVM,由KVM负责处理这个VM exit。
1 | |
1.5 一个简单KVM用户空间实例
先做一下概念辨析:
- 创建虚拟机(Create VM):这指的是在虚拟化平台(如 KVM、VMware、Hyper-V 等)中,建立一个虚拟机的实例。在这一步骤中,你为虚拟机分配资源,配置硬件特性,如内存、处理器等。创建虚拟机是虚拟化平台提供的功能,它是设置虚拟机的基本环境。
- 创建 Guest:这指的是在虚拟机内部安装一个操作系统(Guest OS),使虚拟机能够在其内部运行一个独立的操作系统实例。这个操作系统可以是 Windows、Linux 或其他支持的操作系统。在创建 Guest 时,你需要安装操作系统的镜像文件,进行操作系统的配置和设置,就像在物理硬件上安装操作系统一样。
通过一个具体的KVM用户空间的实例,我们可以总结CPU虚拟化的关键概念和步骤。在这个实例中,我们将代码放在一个名为kvm.c的文件中,主要涵盖以下几个要点:
- 虚拟机(VM)结构体(vm):表示一台虚拟机,包含基本的计算机组件,如处理器和内存。每个虚拟机可以包含多个处理器,每个处理器有自己的状态(寄存器)。
- 处理器(VCPU)结构体(vcpu):表示一个虚拟的处理器。在这个实例中,我们只虚拟了一个vcpu。每个vcpu具有自己的寄存器状态,如通用寄存器和特殊寄存器。
- 用户空间与内核通信:用户空间通过文件描述符/dev/kvm 与内核中的KVM模块进行通信。在实例中,我们使用全局变量g_dev_fd 来记录打开的/dev/kvm 文件描述符。
1 | |
main函数首先对这些变量进行了初始化,然后调用setup_vm开始组装机器了。组装好机器后,调用load_image加载Guest的镜像到内存中,最后调用run_rm开始执行Guest:
1 | |
1.5.1 创建虚拟机实例
这段代码用于创建一个虚拟机实例,首先调用 ioctl 函数发送 KVM_CREATE_VM 命令给内核的 KVM 子系统,从而在内核中创建了一个虚拟机实例,并返回了虚拟机实例的文件描述符。在后续的代码中,可以通过这个文件描述符来操作该虚拟机实例
最初创建的虚拟机只是一个空机箱,既没有内存,也没有处理器
1 | |
1.5.2 创建内存
组装机器,首先是内存,就像需要在内存槽上插上内存条一样,我们也需要为我们的虚拟机安装内存。KVM为用户空间工具配置虚拟机内存定义的数据结构如下:
1 | |
这段代码定义了一个结构体,用于配置虚拟机中的内存区域。其中,slot 字段表示内存槽编号,用于标识内存的插槽。flags 字段表示内存的类型和属性,如 KVM_MEM_READONLY 表示只读内存。guest_phys_addr 字段指定插入的内存在虚拟机的物理地址空间中的起始地址。memory_size 字段表示内存的大小,以字节为单位。userspace_addr 字段表示宿主机中分配的内存的起始地址,用于在宿主机和虚拟机之间进行内存映射。
下面这段代码的主要功能是为虚拟机配置物理内存。它首先使用 mmap 分配一段按照页面尺寸对齐的内存作为虚拟机的物理内存。然后,通过 KVM_SET_USER_MEMORY_REGION API,将这块内存插入虚拟机的内存槽中。在 setup_vm 函数中,填充了虚拟机内存配置结构体 vm->mem 的各个字段,包括内存槽编号、内存大小、内存在虚拟机物理地址空间的起始地址以及在宿主机中的起始地址。最后,通过 ioctl 调用将内存配置信息传递给 KVM 子系统,将这块内存插入虚拟机的0号槽(使用mmap分配了一段按照页面尺寸对齐的64MB的内存作为虚拟机的物理内存。然后通过KVM子系统为用户空间配置虚拟机内存提供的API KVM_SET_USER_MEMORY_REGION,为虚拟机在0号槽上插入一条内存)。
1 | |
1.5.3 创建处理器
KVM模块为用户空间提供的API为KVM_CREATE_VCPU,这个API接收一个参数vcpu id,本质上是lapci id:
在 setup_vm 函数中,首先获取虚拟机中的第一个处理器实例,然后通过 KVM_CREATE_VCPU 命令,为虚拟机创建一个处理器。创建后,处理器的文件描述符 fd 将用于与该处理器实例进行交互。
1 | |
在虚拟处理器创建完成后,我们需要告知处理器从虚拟机内存的哪个位置开始执行指令。这可以通过直接设置代码段(cs)和指令指针(RIP)来实现,而不需要按照传统的方式执行,如处理器重置后从地址0xFFFFFFF0开始执行。在x86架构中,KVM为虚拟处理器的寄存器定义了两个结构体,其中一个是struct kvm_sregs,该结构体被称为特殊寄存器(special registers),它包括了各种段寄存器、控制寄存器等。代码段寄存器cs 就在这个结构体中。
1 | |
通用寄存器、标志寄存器,以及前面刚刚提到的指令指针寄存器
eip定义在另一个结构体kvm_regs中:
1 | |
在系统启动时,首先进入16位实模式,并在后续将Guest加载到段地址为0x1000、偏移地址为0的内存位置。为了实现这个目标,代码中使用了KVM API来设置虚拟处理器的寄存器值,包括代码段寄存器(cs)和指令指针寄存器(RIP),以及一些附加操作。下面是对文字和代码的解释和注释:
1 | |
1.5.4 Guest
实现一个非常小的Guest:这个Guest就是一个简单的无限循环
这个Guest的内核中没有任何文件格式解码器,需要将Guest编译为无格式的,因此我们需要使用objcopy从ELF格式转换为binary格式,代码从地址0开始。这个Guest没有任何依赖,所以不连接任何其他的第三方库
1 | |
1.5.5 加载Guest镜像到内存
初始化VCPU时我们将代码段cs设置为0xf000,将rip设置为0,所以这里需要将Guest镜像加载到Guest的内存地址(0x1000<<4)+0x0处。Guest的物理内存的起始地址为ram_start,所以加载Guest镜像到内存的代码如下:
1 | |
这段代码的目的是将Guest镜像文件加载到虚拟机的内存中。它首先打开名为 “./guest/kernel.bin” 的Guest镜像文件,然后通过计算得到Guest镜像应该加载到内存中的物理地址。接下来,通过循环从文件中读取数据,每次最多读取 4096 字节(一个页面的大小),然后将读取的数据写入到内存中。这个过程会一直进行,直到文件的内容被完全读取并写入内存,或者发生了读取错误。在每次循环中,内存指针会被更新,以便在下次循环中写入数据的时候不会覆盖之前的数据。
1.5.6 运行虚拟机
下面是对代码和文本的详细解释:
1 | |
这段代码中的函数 run_vm 是用来启动虚拟机的。它进入了一个无限的循环,每次循环都通过 ioctl 调用发送 KVM_RUN 命令,从而启动虚拟机的运行。在这个循环中,虚拟机会被不断地执行,直到某个条件使得虚拟机退出到用户空间。
在解释完代码后,接下来是对操作步骤的解释:
- 编译 kmm.c 文件:通过执行命令
gcc kvm.c -o kvm,将kvm.c编译成名为kvm的可执行文件。 - 运行虚拟机:通过执行命令
sudo ./kvm,以超级用户权限运行生成的可执行文件。 - 在另一个终端中运行
pidstat命令:执行命令pidstat -ppidof kvm1,监视虚拟机进程的资源使用情况。其中-ppidof kvm`` 参数指定要监视的进程号,1表示每秒输出一次监视结果。 - 观察监视结果:如果一切正常,
pidstat命令的输出会显示每个采样时刻的虚拟机进程的资源利用率。在正常情况下,由于虚拟机中只有一个简单的无限循环,它不会主动触发陷入,因此虚拟机的 CPU 利用率会接近 100%。同时,由于虚拟机并没有进行复杂的操作,因此在 Host 系统态(%system)方面的资源使用率会非常低,接近 0。
这个过程展示了如何使用 KVM 在用户空间创建一个简单的虚拟机,并让虚拟机在无限循环中运行,从而实现虚拟化。