Implement the UNIX program sleep for xv6; your sleep should pause for a user-specified number of ticks. A tick is a notion of time defined by the xv6 kernel, namely the time between two interrupts from the timer chip. Your solution should be in the file user/sleep.c.
Write a program that uses UNIX system calls to ‘’ping-pong’’ a byte between two processes over a pair of pipes, one for each direction. The parent should send a byte to the child; the child should print “: received ping”, where is its process ID, write the byte on the pipe to the parent, and exit; the parent should read the byte from the child, print “: received pong”, and exit. Your solution should be in the file user/pingpong.c.
intmain(int argc,char * argv[]) { int fd1[2],fd2[2]; pipe(fd1); pipe(fd2); int pid = fork();
// child // print "<pid>: received ping" // write back to parent a byte and exit // close fd[1] // zero for read and 1 for read if(pid==0) { close(fd1[1]);//close write close(fd2[0]);//close read char buf[3]; read(fd1[0],&buf,1);//read a byte from parent printf("%d: received ping\n",getpid()); write(fd2[1],&buf,1);//write back to parent exit(0); }
// parent // send a byte to the child // close fd[0] else { close(fd1[0]);//close read close(fd2[1]);//close write char buf[3]; write(fd1[1],"A",1);// send a byte to the child read(fd2[0],&buf,1); printf("%d: received pong\n",getpid()); } exit(0); }
primes
Write a concurrent version of prime sieve using pipes. This idea is due to Doug McIlroy, inventor of Unix pipes. The picture halfway down this page and the surrounding text explain how to do it. Your solution should be in the file user/primes.c.
Your goal is to use pipe and fork to set up the pipeline. The first process feeds the numbers 2 through 35 into the pipeline. For each prime number, you will arrange to create one process that reads from its left neighbor over a pipe and writes to its right neighbor over another pipe. Since xv6 has limited number of file descriptors and processes, the first process can stop at 35.
Write a simple version of the UNIX find program: find all the files in a directory tree whose name matches a string. Your solution should be in the file user/find.c.
Write a simple version of the UNIX xargs program: read lines from the standard input and run a command for each line, supplying the line as arguments to the command. Your solution should be in the file user/xargs.c.
对于管道连接的命令,以find . b | xargs grep hello为例,argv[0]是 xargs,argv[1]是grep,一共有三个参数,如果想要读取find . b,那么需要从标准输入中读取,也即是使用read函数读取fd为0时的数据
// Per-process state structproc { structspinlocklock;
// p->lock must be held when using these: enumprocstatestate;// Process state structproc *parent;// Parent process void *chan; // If non-zero, sleeping on chan int killed; // If non-zero, have been killed int xstate; // Exit status to be returned to parent's wait int pid; // Process ID
// these are private to the process, so p->lock need not be held. uint64 kstack; // Virtual address of kernel stack uint64 sz; // Size of process memory (bytes) pagetable_t pagetable; // User page table structtrapframe *trapframe;// data page for trampoline.S structcontextcontext;// swtch() here to run process structfile *ofile[NOFILE];// Open files structinode *cwd;// Current directory char name[16]; // Process name (debugging)
// Create a new process, copying the parent. // Sets up child kernel stack to return as if from fork() system call. int fork(void) { int i, pid; structproc *np; structproc *p = myproc();
In this assignment you will add a system call, sysinfo, that collects information about the running system. The system call takes one argument: a pointer to a struct sysinfo (see kernel/sysinfo.h). The kernel should fill out the fields of this struct: the freemem field should be set to the number of bytes of free memory, and the nproc field should be set to the number of processes whose state is not UNUSED. We provide a test program sysinfotest; you pass this assignment if it prints “sysinfotest: OK”.
// p->lock must be held when using these: enumprocstatestate;// Process state structproc *parent;// Parent process void *chan; // If non-zero, sleeping on chan int killed; // If non-zero, have been killed int xstate; // Exit status to be returned to parent's wait int pid; // Process ID
// these are private to the process, so p->lock need not be held. uint64 kstack; // Virtual address of kernel stack uint64 sz; // Size of process memory (bytes) pagetable_t pagetable; // User page table structtrapframe *trapframe;// data page for trampoline.S structcontextcontext;// swtch() here to run process structfile *ofile[NOFILE];// Open files structinode *cwd;// Current directory char name[16]; // Process name (debugging) int mask; };
voiddfs_vmprint(pagetable_t pagetable,int level) { // there are 2^9 = 512 PTEs in a page table. for(int i = 0; i < 512; i++){ pte_t pte = pagetable[i]; if((pte & PTE_V)){//只要有效就打印出来 // this PTE points to a lower-level page table.
hart 2 starting hart 1 starting page table 0x0000000087f6e000 ..0: pte 0x0000000021fda801 pa 0x0000000087f6a000 .. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000 .. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000 .. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000 .. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000 ..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000 .. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000 .. .. ..510: pte 0x0000000021fdd807 pa 0x0000000087f76000 .. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000 init: starting sh $
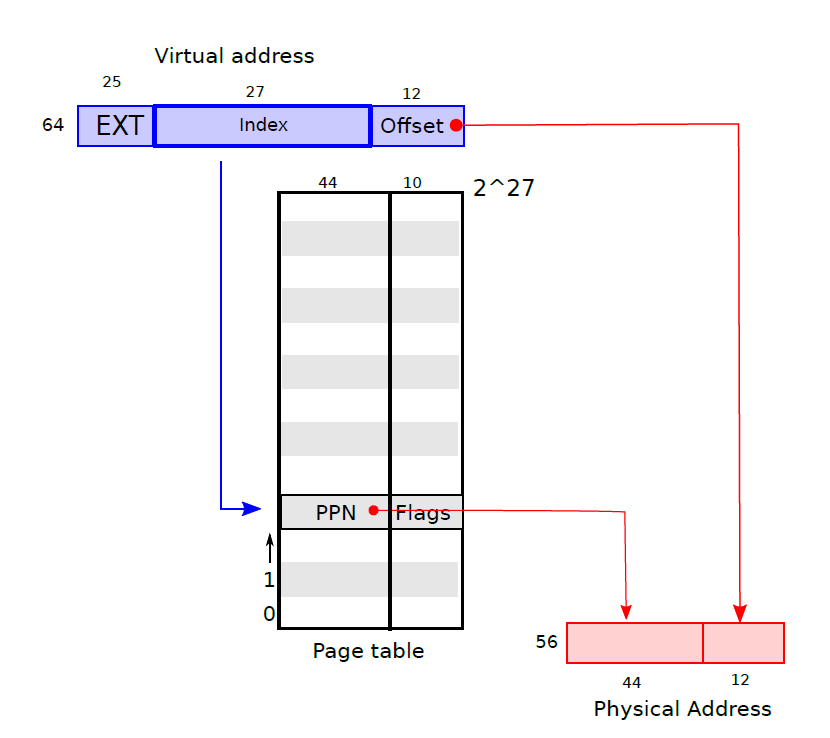
A kernel page table per process
Xv6只有一个内核页表,只要在内核中执行,就会使用它。内核页表是物理地址的直接映射,也即是内核虚拟地址 x 映射到物理地址 x。每个进程也会有自己的用户页表,该页表只包含此进程的用户空间的地址映射。而这些用户页表和用户地址在内核页表中是不存在的。因此就会出现一个问题:假设用户进程调用write系统调用并传递一个指针,由于该指针是用户级的地址,在内核中是无效的,因此实际过程中会先将用户级的虚拟地址转换为物理地址,这样就会造成一定程度的开销。本任务就是为了解决这个问题,让每个用户级的进程都有一个内核页表
// Per-process state structproc { structspinlocklock;
// p->lock must be held when using these: enumprocstatestate;// Process state structproc *parent;// Parent process void *chan; // If non-zero, sleeping on chan int killed; // If non-zero, have been killed int xstate; // Exit status to be returned to parent's wait int pid; // Process ID
// these are private to the process, so p->lock need not be held. uint64 kstack; // Virtual address of kernel stack uint64 sz; // Size of process memory (bytes) pagetable_t pagetable; // User page table structtrapframe *trapframe;// data page for trampoline.S structcontextcontext;// swtch() here to run process structfile *ofile[NOFILE];// Open files structinode *cwd;// Current directory char name[16]; // Process name (debugging) pagetable_t kpgtable; // Kernel page table };
后面要用的几个重要函数
函数名称
作用
walk
通过虚拟地址得到 PTE
mappages
将虚拟地址映射到物理地址
copyin
将用户虚拟地址的数据复制到内核空间地址
copyout
将内核数据复制到用户虚拟地址
kvminit
创建内核的页表,对全局的kernel_pagetable进行映射
kvmmap
调用 mappages,将一个虚拟地址范围映射到一个物理地址范围
kvminithart
映射内核页表。它将根页表页的物理地址写入寄存器 satp 中
procinit
为每个进程分配一个内核栈
kalloc
分配物理页
proc_pagetable(struct proc *p)
为给定的进程创建用户态页表
kvminithart
映射内核页表。它将根页表页的物理地址写入寄存器 satp 中
相关函数调用链:
1 2 3 4
main kvminit -> kvmmap procinit userinit -> allocproc
// map kernel text executable and read-only. kvmmap(KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of. kvmmap((uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to // the highest virtual address in the kernel. kvmmap(TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X); }
// add a mapping to the kernel page table. // only used when booting. // does not flush TLB or enable paging. void kvmmap(uint64 va, uint64 pa, uint64 sz, int perm) { if(mappages(kernel_pagetable, va, sz, pa, perm) != 0) panic("kvmmap"); }
// Allocate a page for the process's kernel stack. // Map it high in memory, followed by an invalid // guard page. char *pa = kalloc(); if(pa == 0) panic("kalloc"); uint64 va = KSTACK((int) (p - proc)); kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W); p->kstack = va;
// free a proc structure and the data hanging from it, // including user pages. // p->lock must be held. staticvoid freeproc(struct proc *p) { if(p->trapframe) kfree((void*)p->trapframe); p->trapframe = 0; if(p->pagetable) proc_freepagetable(p->pagetable, p->sz); /* add here */ if (p->kstack) { pte_t* pte = walk(p->kpgtable, p->kstack, 0); if (pte == 0) panic("freeproc: walk"); kfree((void*)PTE2PA(*pte)); } p->kstack = 0;
// Per-CPU process scheduler. // Each CPU calls scheduler() after setting itself up. // Scheduler never returns. It loops, doing: // - choose a process to run. // - swtch to start running that process. // - eventually that process transfers control // via swtch back to the scheduler. void scheduler(void) { structproc *p; structcpu *c = mycpu();
c->proc = 0; for(;;){ // Avoid deadlock by ensuring that devices can interrupt. intr_on();
int found = 0; for(p = proc; p < &proc[NPROC]; p++) { acquire(&p->lock); if(p->state == RUNNABLE) { // Switch to chosen process. It is the process's job // to release its lock and then reacquire it // before jumping back to us. p->state = RUNNING; c->proc = p; //切换到进程自己的内核页表处 w_satp(MAKE_SATP(p->kpgtable)); //使用sfence.vma刷新当前 CPU 的 TLB sfence_vma(); //调度进程 swtch(&c->context, &p->context); //切换回内核页表 kvminithart();
// Process is done running for now. // It should have changed its p->state before coming back. c->proc = 0;
// Create a new process, copying the parent. // Sets up child kernel stack to return as if from fork() system call. int fork(void) { int i, pid; structproc *np; structproc *p = myproc();
The output depends on that fact that the RISC-V is little-endian. If the RISC-V were instead big-endian what would you set i to in order to yield the same output? Would you need to change 57616 to a different value?
// Per-process state structproc { structspinlocklock;
// p->lock must be held when using these: enumprocstatestate;// Process state structproc *parent;// Parent process void *chan; // If non-zero, sleeping on chan int killed; // If non-zero, have been killed int xstate; // Exit status to be returned to parent's wait int pid; // Process ID
// these are private to the process, so p->lock need not be held. uint64 kstack; // Virtual address of kernel stack uint64 sz; // Size of process memory (bytes) pagetable_t pagetable; // User page table structtrapframe *trapframe;// data page for trampoline.S structcontextcontext;// swtch() here to run process structfile *ofile[NOFILE];// Open files structinode *cwd;// Current directory char name[16]; // Process name (debugging)
int alarm_interval; //n in sigalarm(n, (void(*)())(fn)); void(*alarm_handler)();// fn in sigalarm(n, (void(*)())(fn)); int alarm_ticks;//after alarm_ticks will structtrapframe *saved_trapframe; int alarm_flag; };
// Look in the process table for an UNUSED proc. // If found, initialize state required to run in the kernel, // and return with p->lock held. // If there are no free procs, or a memory allocation fails, return 0. static struct proc* allocproc(void) { structproc *p;
// free a proc structure and the data hanging from it, // including user pages. // p->lock must be held. staticvoid freeproc(struct proc *p) { if(p->trapframe) kfree((void*)p->trapframe); p->trapframe = 0;